As I get older, I find myself forgetting things—a lot. But, thanks to smartphone technology, I have learned how to manage my forgetfulness by using the “Notes” app on my iPhone.
Figure 1: The Apple Notes app icon. Image credit: Wikipedia
This app makes it easy for me to:
Jot down ideas that suddenly come to me
List books I want to read and websites I want to visit
Make note of musical artists I want to check out
Record “to do” and grocery lists
Write down details I need to have at my fingertips when I travel
List new scientific discoveries with implications for the RTB creation model that I want to blog about, such as the recent discovery of a protein grammar calling attention to the elegant design of biochemical systems
And the list goes on. I will never forget, again!
On top of that, I can use the Notes app to categorize and organize all my notes and house them in a single location. Thus, I don’t have to manage scraps of paper that invariably wind up getting scattered all over the place—and often lost.
And, as a bonus, the Notes app anticipates the next word I am going to use even before I type it. I find myself relying on this feature more and more. It is much easier to select a word than type it out. In fact, the more I use this feature, the better the app becomes at anticipating the next word I want to type.
Recently, a team of bioinformaticists from the University of Alabama, Birmingham (UAB) and the National Institutes of Health (NIH) used the same algorithm the Notes app uses to anticipate word usage to study protein architectures.1 Their analysis reveals new insight into the structural features of proteins and also highlights the analogy between the information housed in these biomolecules and human language. This analogy contributes to the revitalized Watchmaker argument presented in my book The Cell’s Design.
N-Gram Language Modeling
The algorithm used by the Notes app to anticipate the next word the user will likely type is called n-gram language modeling. This algorithm determines the probability of a word being used based on the previous word (or words) typed. (If the probability is based on a single word, it is called a unigram probability. If the calculation is based on the previous two words, it is called a bigram probability, and so on.) This algorithm “trains” the Notes app so that the more I use it, the more reliable the calculated probabilities—and, hence, the better the word recommendations.
N-Gram Language Modeling and the Case for a Creator
To understand why the work of research team from UAB and NIH provides evidence for a Creator’s role in the origin and design of life, a brief review of protein structure is in order.
Protein Structure
Proteins are large complex molecules that play a key role in virtually all of the cell’s operations. Biochemists have long known that the three-dimensional structure of a protein dictates its function.
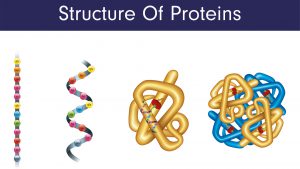
Because proteins are such large complex molecules, biochemists categorize protein structure into four different levels: primary, secondary, tertiary, and quaternary structures. A protein’s primary structure is the linear sequence of amino acids that make up each of its polypeptide chains.
The secondary structure refers to short-range three-dimensional arrangements of the polypeptide chain’s backbone arising from the interactions between chemical groups that make up its backbone. Three of the most common secondary structures are the random coil, alpha(α) helix, and beta(β) pleated sheet.
Tertiary structure describes the overall shape of the entire polypeptide chain and the location of each of its atoms in three-dimensional space. The structure and spatial orientation of the chemical groups that extend from the protein backbone are also part of the tertiary structure.
Quaternary structure arises when several individual polypeptide chains interact to form a functional protein complex.
Figure 2: The four levels of protein structure. Image credit: Shutterstock
Protein Domains
Within the tertiary structure of proteins, biochemists have discovered compact, self-contained regions that fold independently. These three-dimensional regions of the protein’s structure are called domains. Some proteins consist of a single compact domain, but many proteins possess several domains. In effect, domains can be thought to be the fundamental units of a protein’s tertiary structure. Each domain possesses a unique biochemical function. Biochemists refer to the spatial arrangement of domains as a protein’s domain architecture.
Researchers have discovered several thousand distinct protein domains. Many of these domains recur in different proteins, with each protein’s tertiary structure comprised of a mix-and-match combination of protein domains. Biochemists have also learned that a relationship exists between the complexity of an organism and the number of unique domains found in its set of proteins and the number of multi-domain proteins encoded by its genome.
Figure 3: Pyruvate kinase, an example of a protein with three domains. Image credit: Wikipedia
The Key Question in Protein Chemistry
As much progress as biochemists have made characterizing protein structure over the last several decades, they still lack a fundamental understanding of the relationship between primary structure (the amino acid sequence) and tertiary structure and, hence, protein function. In order to develop this insight, they need to determine the “rules” that dictate the way proteins fold. Treating proteins as information systems can help determine some of these rules.
Protein as Information Systems
Proteins are not only large, complex molecules but also information-harboring systems. The amino acid sequence that defines a protein’s primary structure is a type of information—biochemical information—with the individual amino acids analogous to the letters that make up an alphabet.
N-Gram Analysis of Proteins
To gain insight into the relationship between a protein’s primary structure and its tertiary structures, the researchers from UAB and NIH carried out an n-gram analysis on the 23 million protein domains found in the protein sets of 4,800 species found across all three domains of life.
These researchers point out that an individual amino acid in a protein’s primary structure doesn’t contain information just as an individual letter in an alphabet doesn’t harbor any meaning. In human language, the most basic unit that conveys meaning is a word. And, in proteins, the most basic unit that conveys biochemical meaning is a domain.
To decipher the “grammar” used by proteins, the researchers treated adjacent pairs of protein domains in the tertiary structure of each protein in the sample set as a bigram (similar to two words together). Surveying the proteins found in their data set of 4,800 species, they discovered that 95% of all the possible domain combinations don’t exist!
This finding is key. It indicates that there are, indeed, rules that dictate the way domains interact. In other words, just like certain word combinations never occur in human languages because of the rules of grammar, there appears to be a protein “grammar” that constrains the domain combinations in proteins. This insight implies that physicochemical constraints (which define protein grammar) dictate a protein’s tertiary structure, preventing 95% of conceivable domain-domain interactions.
Entropy of Protein Grammar
In thermodynamics, entropy is often used as a measure of the disorder of a system. Information theorists borrow the concept of entropy and use it to measure the information content of a system. For information theorists, the entropy of a system is indirectly proportional to the amount of information contained in a sequence of symbols. As the information content increases, the entropy of the sequence decreases, and vice versa. Using this concept, the UAB and NIH researchers calculated the entropy of the protein domain combinations.
In human language, the entropy increases as the vocabulary increases. This makes sense because, as the number of words increases in a language, the likelihood that random word combinations would harbor meaning decreases. In like manner, the research team discovered that the entropy of the protein grammar increases as the number of domains increases. (This increase in entropy likely reflects the physicochemical constraints—the protein grammar, if you will—on domain interactions.)
Human languages all carry the same amount of information. That is to say, they all display the same entropy content. Information theorists interpret this observation as an indication that a universal grammar undergirds all human languages. It is intriguing that the researchers discovered that the protein “languages” across prokaryotes and eukaryotes all display the same level of entropy and, consequently, the same information content. This relationship holds despite the diversity and differences in complexity of the organism in their data set. By analogy, this finding indicates that a universal grammar exists for proteins. Or to put it another way, the same set of physicochemical constraints dictate the way protein domains interact for all organisms.
At this point, the researchers don’t know what the grammatical rules are for proteins, but knowing that they exist paves the way for future studies. It also generates hope that one day biochemists might understand them and, in turn, use them to predict protein structure from amino acid sequences.
This study also illustrates how fruitful it can be to treat biochemical systems as information systems. The researchers conclude that “The similarities between natural languages and genomes are apparent when domains are treated as functional analogs of words in natural languages.”2
In my view, it is this relationship that points to a Creator’s role in the origin and design of life.
Protein Grammar and the Case for a Creator
As discussed in The Cell’s Design, the recognition that biochemical systems are information-based systems has interesting philosophical ramifications. Common, everyday experience teaches that information derives solely from the activity of human beings. So, by analogy, biochemical information systems, too, should come from a divine Mind. Or at least it is rational to hold that view.
But the case for a Creator strengthens when we recognize that it’s not merely the presence of information in biomolecules that contributes to this version of a revitalized Watchmaker analogy. Added vigor comes from the UAB and NIH researchers’ discovery that the mathematical structure of human languages and biochemical languages is identical.
Skeptics often dismiss the updated Watchmaker argument by arguing that biochemical information is not genuine information. Instead, they maintain that when scientists refer to biomolecules as harboring information, they are employing an illustrative analogy—a scientific metaphor—and nothing more. They accuse creationists and intelligent design proponents of misconstruing their use of analogical language to make the case for design.3
But the UAB and NIH scientists’ work questions the validity of this objection. Biochemical information has all of the properties of human language. It really is information, just like the information we conceive and use to communicate.
Is There a Biochemical Anthropic Principle?
This discovery also yields another interesting philosophical implication. It lends support to the existence of a biochemical anthropic principle. Discovery of a protein grammar means that there are physicochemical constraints on protein structure. It is remarkable to think that protein tertiary structures may be fundamentally dictated by the laws of nature, instead of being the outworking of an historically contingent evolutionary history. To put it differently, the discovery of a protein grammar reveals that the structure of biological systems may reflect some deep, underlying principles that arise from the very nature of the universe itself. And yet these structures are precisely the types of structures life needs to exist.
I interpret this “coincidence” as evidence that our universe has been designed for a purpose. And as a Christian, I find that notion to resonate powerfully with the idea that life manifests from an intelligent Agent—namely, God.
Lijia Yu et al., “Grammar of Protein Domain Architectures,” Proceedings of the National Academy of Sciences, USA 116, no. 9 (February 26, 2019): 3636–45, doi:10.1073/pnas.1814684116.
Yu et al., 3636–45.
For example, see Massimo Pigliucci and Maarten Boudry, “Why Machine-Information Metaphors Are Bad for Science and Science Education,” Science and Education 20, no. 5–6 (May 2011): 453–71; doi:10.1007/s11191-010-9267-6.
Sometimes bigger is better, and other times, not so much—particularly for scientists working in the field of nanotechnology. Scientists and engineers working in this...





{kind=link}
{kind=link}


